MIPS 学习
MIPS指令
MIPS的指令特点
所有指令都是32位编码;
有些指令有26位供目标地址编码;有些则只有16位。因此要想加载任何一个32位值,就得用两个加载指令。
所有的动作原理上要求必须在1个时钟周期内完成,一个动作一个阶段;
有32个通用寄存器,每个寄存器32位(对32位机)或64位(对64位机);
本身没有任何帮助运算判断的标志寄存器,要实现相应的功能时,是通过测试两个寄存器是否相等来完成的;
所有的运算都是基于32位的,没有对字节和对半字的运算(MIPS里,字定义为32位,半字定义为16位);
没有单独的栈指令,所有对栈的操作都是统一的内存访问方式。因为push和pop指令实际上是一个复合操作,包含对内存的写入和对栈指针的移动;
由于MIPS固定指令长度,所以造成其编译后的二进制文件和内存占用空间比x86的要大,(x86平均指令长度只有3个字节多一点,而MIPS是4个字节);
寻址方式:只有一种内存寻址方式。就是基地址加一个16位的地址偏移;
内存中的数据访问必须严格对齐(至少4字节对齐);
跳转指令只有26位目标地址,再加上2位的对齐位,可寻址28位的空间,即256M。意思即是说,在一个C程序内,goto语句只能跳转到它之前的128M和之后的128M这个地址空间之内;
条件分支指令只有16位跳转地址,加上2位的对齐位,共18位寻址空间,即256K。意思即是说,在一个C程序内,if语句只能跳转到它之前的128K和之后的128K这个地址空间之内;
MIPS默认不把子函数的返回地址(就是调用函数的受害指令地址)存放到栈中,而是存放到R31寄存器中;这对那些叶子函数有利。如果遇到嵌套的函数的话,有另外的机制处理;
流水线效应。由于采用了高度的流水线,结果产生了一些对程序员来说可见的效应,需要注意。最重要的两个效应就是分支延迟效应和载入延迟效应。
五级流水线
每条指令都包含五个执行阶段。
- 第一阶段:从指令缓冲区中取指令。占一个时钟周期;
- 第二阶段:从指令中的源寄存器域(可能有两个)的值(为一个数字,指定\$0~\$31中的某一个)所代表的寄存器中读出数据。占半个时钟周期;
- 第三阶段:在一个时钟周期内做一次算术或逻辑运算。占一个时钟周期;
- 第四阶段:指令从数据缓冲中读取内存变量的阶段。从平均来讲,大约有3/4的指令在这个阶段没做什么事情,但它是指令有序性的保证。占一个时钟周期;
- 第五阶段:存储计算结果到缓冲或内存的阶段。占半个时钟周期;
所以一条指令要占用四个时钟周期。
分支延迟槽
- 任何一个分支跳转语句后面的那条语句叫做分支延迟槽。实际上在程序执行到分支语句时,当它刚把要跳转到的地址填充好(到代码计数器里),还没完成本条指令,分支语句后面的那条指令就执行了。这是因为流水线效应,几条指令同时在执行,只是处于不同的阶段。分支延迟槽常用被利用起来完成一些参数初始化等相关工作,而不是被浪费了。
载入延迟
- 载入延迟是这样的,当执行一条从内存中载入数据的指令时,是先载入到高速缓冲中,然后再取到寄存器中,这个过程相对来说是比较慢的。在这个过程完成之前,可能已经有几条在流水线上的指令被执行了。这几条在载入数据指令后被执行的指令就被称作载入延迟槽。现在就有一个问题,如果后面这几条指令要用到载入数据指令所载入的那个数据怎么办?一个通用的办法是,把内部锁加在数据载入过程上,这样,当后面的指令要用这个数据时,就只有先停止运行(在ALU阶段),等这条载入数据指令完成了后再开始运行。
MIPS的指令格式
MIPS的所有指令都是32位的,指令格式简单。不像x86那样,x86的指令长度不是固定的,以80386为例, 其指令长度可从1字节(例如PUSH)到17字节,这样的好处代码密度高,所以MIPS的二进制文件要比x86的大大约20%~30%。而定长指令和格式简单的好处是易于译码和更符合流水线操作,由于指令中指定的寄存器位置是固定的,使得译码过程和读指令的过程可以同时进行,即固定字段译码。
为了让指令的格式刚好合适,于是设计者做了一个折衷:所有指令定长,但是不同的指令有不同的格式。MIPS指令有三种格式:R格式,I格式,J格式。每种格式都由若干字段(filed)组成,图示如下:
I型指令
| 6 | 5 | 5 | 16 |
|---|---|---|---|
| op | rs | rt | 立即数操作 |
- 加载/存储字节,半字,字,双字
- 条件分支,跳转,跳转并链接寄存器
R型指令
| 6 | 5 | 5 | 5 | 5 | 6 |
|---|---|---|---|---|---|
| op | rs | rt | rd | shamt | funct |
- 寄存器-寄存器ALU操作
- 读写专用寄存器
J型指令
| 6 | 26 |
|---|---|
| op | 跳转地址 |
- 跳转,跳转并链接
- 陷阱和从异常中返回
各字段含义
- op: 指令基本操作,称为操作码。
- rs: 第一个源操作数寄存器。
- rt: 第二个源操作数寄存器。
- rd: 存放操作结果的目的操作数寄存器。
- shamt: 位移量
- funct: 函数,这个字段选择op操作的某个特定变体。
跳转范围
J指令的地址字段为26位,用于跳转目标。指令在内存中以4字节对齐,最低两个有效位不需要存储。在MIPS中,每个地址的最低两位指定了字的一个字 节,cache映射的下标是不使用这两位的,这样能表示28位的字节编址,允许的地址空间为256M。PC是32位的,那其它4位从何而来呢?MIPS的跳转指令只替换PC的低28位,而高4位保留原值。因此,加载和链接程序必须避免跨越256MB,在256M的段内,分支跳转地址当作一个绝对地址,和PC无关。
如果超过256M(段外跳转)就要用跳转寄存器指令了。
同样,条件分支指令中的16位立即数如果不够用,可以使用PC相对寻址,即用分支指令中的分支地址与(PC+4)的和做分支目标。由于一般的循环和if语句都小于2^16个字(2的16次方),这样的方法是很理想的。
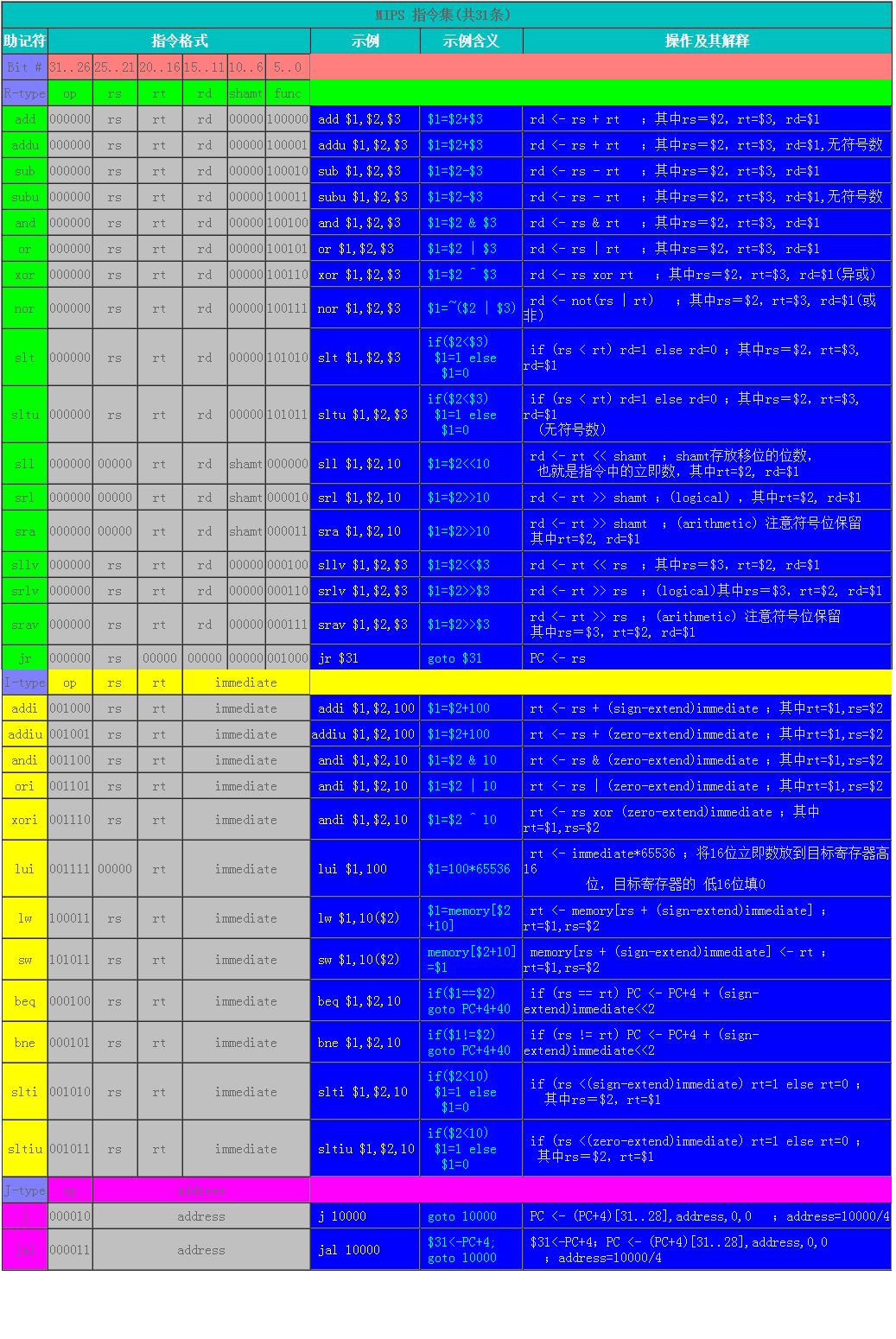
31条MIPS指令
MIPS的通用寄存器
MIPS CPU有32个通用寄存器(GPR),\$0到\$31。
寄存器分配在编译优化中是最重要的优化之一(也许是做重要的)。现在的寄存器分配算法都是基于图着色的技术。其基本思想是构造一个图,用以代表分配寄存器的各个方案,然后用此图来分配寄存器。粗略说来就是使用有限的颜色使图中相临的节点着以不同的颜色,图着色问题是个图大小的指数函数,有些启发式算法产生近乎线形时间运行的分配。全局分配中如果有16个通用寄存器用于整型变量,同时另有额外的寄存器用于浮点数,那么图着色会很好的工作。在寄存器数较少时候图着色并不能很好的工作。
问: 既然不能少于16个,那为什么不用64个呢?
答: 使用64个或更多寄存器不但需要更大的指令空间来对寄存器编码,还会增加上下文切换的负担。除了那些很大非常复杂的函数,32个寄存器就已足够保存经常使用的数据。使用更多的寄存器并不必要,同时计算机设计有个原则叫“越小越快”,但是也不是说使用31个寄存器会比32个性能更好,32个通用寄存器是流行的做法。
\$0: 即\$zero,该寄存器总是返回零,为0这个有用常数提供了一个简洁的编码形式。MIPS编译器使用slt,beq,bne等指令和由寄存器\$0获得的0来产生所有的比较条件:相等,不等,小于,小于等于,大于,大于等于。还可以用add指令创建move伪指令,即
move $t0,$t1 |
实际为add $t0,$0,$t1
使用伪指令可以简化任务,使汇编程序提供了比硬件更丰富的指令集。
\$1: 即\$at,该寄存器为汇编保留,刚才说到使用伪指令可以简化任务,但是代价就是要为汇编程序保留一个寄存器,就是\$at。由于I型指令的立即数字段只有16位,在加载大常数时,编译器或汇编程序需要把大常数拆开,然后重新组合到寄存器里。
比如加载一个32位立即数需要lui(装入高位立即数)和addi两条指令。像MIPS程序拆散和重装大常数由汇编程序来完成,汇编程序必需一个临时寄存器来重组大常数,这也是为汇编保留\$at的原因之一。如果你要显示的使用这个寄存器(比如在异常处理程序中保存和恢复寄存器),有一个汇编directive可被用来禁止汇编器在directive之后再使用at寄存器(但是汇编的一些宏指令将因此不能再可用)。
\$2..\$3: (\$v0-\$v1)用于子程序的非浮点结果或返回值,对于子程序如何传递参数及如何返回,MIPS范围有一套约定,堆栈中少数几个位置处的内容装入CPU寄存器,其相应内存位置保留未做定义,当这两个寄存器不够存放返回值时,编译器通过内存来完成。
\$4..\$7: (\$a0-\$a3)用来传递前四个参数给子程序,不够的用堆栈。a0-a3和v0-v1以及ra一起来支持子程序/过程调用,分别用以传递参数,返回结果和存放返回地址。当需要使用更多的寄存器时,就需要堆栈了,MIPS编译器总是为参数在堆栈中留有空间以防有参数需要存储。
\$8..\$15: (\$t0-\$t7)临时寄存器,子程序可以使用它们而不用保留。
\$16..\$23: (\$s0-\$s7)保存寄存器,在过程调用过程中需要保留(被调用者保存和恢复,还包括\$fp和\$ra),MIPS提供了临时寄存器和保存寄存器,这样就减少了寄存器溢出(spilling,即将不常用的变量放到存储器的过程),编译器在编译一个叶(leaf)过程(不调用其它过程的过程)的时候,总是在临时寄存器分配完了才使用需要保存的寄存器。
\$24..\$25: (\$t8-\$t9)同(\$t0-\$t7)。
\$26..\$27: (\$k0,\$k1)为操作系统/异常处理保留,至少要预留一个。 异常(或中断)是一种不需要在程序中显示调用的过程。MIPS有个叫异常程序计数器(exception program counter,EPC)的寄存器,属于CP0寄存器,用于保存造成异常的那条指令的地址。查看控制寄存器的唯一方法是把它复制到通用寄存器里,指令mfc0(move from system control)可以将EPC中的地址复制到某个通用寄存器中,通过跳转语句(jr),程序可以返回到造成异常的那条指令处继续执行。仔细分析一下会发现个有意思的事情:
为了查看控制寄存器EPC的值并跳转到造成异常的那条指令(使用jr),必须把EPC的值到某个通用寄存器里,这样的话,程序返回到中断处时就无法将所有的寄存器恢复原值。如果先恢复所有的寄存器,那么从EPC复制过来的值就会丢失,jr就无法返回中断处;如果我们只是恢复除有从EPC复制过来的返回地址外的寄存器,但这意味着程序在异常情况后某个寄存器被无端改变了,这是不行的。为了摆脱这个两难境地,MIPS程序员都必须保留两个寄存器\$k0和\$k1,供操作系统使用。发生异常时,这两个寄存器的值不会被恢复,编译器也不使用k0和k1,异常处理函数可以将返回地址放到这两个中的任何一个,然后使用jr跳转到造成异常的指令处继续执行。
\$28: (\$gp)C语言中有两种存储类型,自动型和静态型,自动变量是一个过程中的局部变量。静态变量是进入和退出一个过程时都是存在的。为了简化静态数据的访问,MIPS软件保留了一个寄存器:全局指针gp(global pointer,\$gp),如果没有全局指针,从静态数据去装入数据需要两条指令:一条有编译器和链接器计算的32位地址常量中的有效位;另一条才真正装入数据。全局指针指向静态数据区中的运行时决定的地址,在存取位于gp值上下32KB范围内的数据时,只需要一条以gp为基指针的指令即可。在编译时,数据须在以gp为基指针的64KB范围内。
\$29: (\$sp)MIPS硬件并不直接支持堆栈,例如,它没有x86的SS,SP,BP寄存器,MIPS虽然定义\$29为栈指针,它还是通用寄存器,只是用于特殊目的而已,你可以把它用于别的目的,但为了使用别人的程序或让别人使用你的程序,还是要遵守这个约定的,但这和硬件没有关系。x86有单独的PUSH和POP指令,而MIPS没有,但这并不影响MIPS使用堆栈。在发生过程调用时,调用者把过程调用过后要用的寄存器压入堆栈,被调用者把返回地址寄存器\$ra和保留寄存器压入堆栈。同时调整堆栈指针,当返回时,从堆栈中恢复寄存器,同时调整堆栈指针。
\$30: (\$fp)GNU MIPS C编译器使用了侦指针(frame pointer),而SGI的C编译器没有使用,而把这个寄存器当作保存寄存器使用(\$s8),这节省了调用和返回开销,但增加了代码生成的复杂性。
\$31: (\$ra)存放返回地址,MIPS 有个jal(jump-and-link,跳转并链接)指令,在跳转到某个地址时,把下一条指令的地址放到\$ra中。用于支持子程序,例如调用程序把参数放到\$a0~\$a3,然后jal X跳到X过程,被调过程完成后把结果放到\$v0,\$v1,然后使用jr \$ra返回。
在调用时需要保存的寄存器为\$a0~\$a3,\$s0~\$s7,\$gp,\$sp,\$fp,\$ra。
MIPS的虚拟地址内存映射空间
- 0x0000 0000 ~ 0x7fff ffff :kuseg 用户级空间,2GB,要经MMU(TLB)地址翻译。可以控制要不要经过缓冲。
- 0x8000 0000 ~ 0x9fff ffff :kseg0,这块区域为操作系统内核所占的区域,共512M。使用时,不经过地址翻译,将最高位去掉就线性映射到内存的低512M(不足的就裁剪掉顶部)。但要经过缓冲区过渡。
- 0xa000 0000 ~ 0xbfff ffff :kseg1,这块区域为系统初始化所占区域,共512M。使用时,不经过地址翻译,也不经过缓冲区。将最高3位去掉就线性映射到内存的低512M(不足的就裁剪掉顶部)。
- 0xc000 0000 ~ 0xffff ffff :kseg2,这块区域也为内核级区域。要经过地址翻译。可以控制要不要经过缓冲。
注意:地址空间的0x0000 0000是不能用的,从0开始的一个或多个页不会被映射。
MIPS的协处理器
在MIPS体系结构中,最多支持4个协处理器(Co-Processor)。其中,协处理器CP0是体系结构中必须实现的。它起到控制CPU的作用。MMU、异常处理、乘除法等功能,都依赖于协处理器CP0来实现。它是MIPS的精髓之一,也是打开MIPS特权级模式的大门。
CP0
CP0:这是MIPS芯片的配置单元。必不可少,虽然叫做协处理器,但是通常都是做在一块芯片上。绝大部分MIPS功能的配置,缓冲的控制,异常/中断的控制,内存管理的控制都在这里面。所以是一个完整的系统所必不可少的。
MIPS的CP0包含32个寄存器。关于它们的资料可以参照MIPS官方的资料MIPS32(R) Architecture For Programmers Volume III: The MIPS32(R) Privileged Resource Architecture的Chap7和Chap8。本文中,仅讨论常见的一些寄存器。
Register 0: Index,作为MMU的索引用。将来讨论MMU和TLB时会详解之。
Register 2, EntryLo0,访问TLB Entry偶数页中的地址低32Bit用。同上,在MMU和TLB的相关章节中详解。
Register 3, EntryLo1,访问TLB Entry奇数页中的地址低32Bit用。
Register 4, Context,用以加速TLB Miss异常的处理。
Register 5, PageMask,用以在MMU中分配可变大小的内存页。
Register 8, BadVAddr,在系统捕获到TLB Miss或Address Error这两种Exception时,发生错误的虚拟地址会储存在该寄存器中。对于引发Exception的Bug的定位来说,这个寄存器非常重要。
Register 9, Count,这个寄存器是R4000以后的MIPS系统引入的。它是一个计数器,计数频率是系统主频的1/2。BCM1125/1250,RMI XLR系列以及Octeon的Cavium处理器均支持该寄存器。对于操作系统来说,可以通过读取该寄存器的值来获取tick的时基。在系统性能测试中,利用该寄存器也可以实现打点计数。
Register 10,EntryHi,这个寄存器同EntryLo0/1一样,用于MMU中。以后会详述。
Register 11,Compare,配合Count使用。当Compare和Count的值相等的时候,会触发一个硬件中断(Hardware Interrupt),并且总是使用Cause寄存器的IP7位。
Register 12,Status,用于处理器状态的控制。
Register 13,Cause,这个寄存器体现了处理器异常发生的原因。
Register 14,EPC,这个寄存器存放异常发生时,系统正在执行的指令的地址。
Register 15,PRID,这个寄存器是只读的,标识处理器的版本信息。向其中写入无意义。
Register 18/19,WatchLo/WatchHi,这对寄存器用于设置硬件数据断点(Hardware Data Breakpoint)。该断点一旦设定,当CPU存取这个地址时,系统就会发生一个异常。这个功能广泛应用于调试定位内存写坏的错误。
Register 28/29,TagLo和TagHi,用于高速缓存(Cache)管理。
下面,我们来详解CP0中常用的几个寄存器,它们是:BadVAddr,Count/Compare,Status/Cause,EPC,WatchLo/WatchHi。
BadVAddr: 错误的虚拟地址。实际上,这个寄存器仅限于出现TLB Miss和ADE (Address Error)两种异常的时候,才能用到。发生错误的虚拟地址会放在这个寄存器里。
一般地,在设定TLB时,通常将0地址附近的一块,设定为无映射区域。这样,一旦编程时不慎访问了空指针(0地址),或是空指针加上一定的偏移量,那么,系统就会抛出一个TLB Miss Exception。在这种情况下,发生错误的地址会被记录在BadVAddr寄存器中。一般地,这个地址是一个非常接近于0的地址。往往地,通过BadVAddr在寄存器中的值,和相关数据结构的分析,就可以找出对应的语句。
另外,对于ADE异常,异常地址也会被保存在BadVAddr中。一般地,操作系统会自行接管这个地址,分两次读取/写入这个地址处的数据,而不会发生Core Dump的情况。但是,如果这个地址既属于非对齐地址,又属于TLB Miss,那么,系统还是会抛出一个Core Dump的。正常地,操作系统应当正确处理这个异常,如果在Exception Handler中发现地址在TLB中未映射,还是应当抛出ADE异常,而不是TLB Miss。Count/Compare: 这两个寄存器是CP0中的一对欢喜冤家。Count是一个计数器,每两个系统时钟周期,Count会增加1,而当它的值和Compare相等时,会发生一个硬件中断(Hardware Interrupt)。这个特性经常用来为操作系统提供一个可靠的tick时脉。
Status: 这个寄存器标识了处理器的状态。其中,中断控制的8个IM(Interrupt Mask)位和设定处理器大小端的RE(Reverse Endianess)位。8个IM位,分别可以控制8个硬件中断源。它们将在讲述‘硬件中断’时详解。RE位很有趣,设定这个Bit可以让CPU在大端(Big Endian)和小端(Little Endian)之间切换。默认情况下,MIPS处理器是大端的,和网络序相同。但是,为了能在MIPS上运行类似Windows NT的服务器操作系统,设定这个Bit可以令处理器工作在Little Endian模式下。
EPC: 这个寄存器的作用很简单,就是保存异常发生时的指令地址。从这个地方可以找到异常发生的指令,再结合BadVAddr, sp, ra等寄存器,就可以推导出异常时的程序调用关系,从而定位问题的根因。一旦异常发生时EPC的内容丢失,那么对异常的定位将是一件非常困难的事情。
WatchLo/WatchHi: 这一对寄存器可以用来设定“内存硬件断点”,也就是对指定点的内存进行监测。当访问的内存地址和这两个寄存器中地址一致时,会发生一个异常。为了适应64Bit的一些扩展功能,某些MIPS处理器又对这两个寄存器的功能做了一些修改,与MIPS体系结构的定义已经有了差别,如RMI的多核处理器等。
Cause: 在处理器异常发生时,这个寄存器标识出了异常的原因。其中,最重要的是从Bit2到Bit6,5个Bit的Excetion Code位。它们标识出了引起异常的原因。
由于协处理器CP0的访问,需要使用特别的指令。这些指令属于“特权级指令”,只有在内核态(Kernel Mode)下才能执行。如果在用户态下,会引起一个异常(Exception)。
CP0 操作指令
对CP0的主要操作有以下的指令:mfc0 rt, rd 将CP0中的rd寄存器内容传输到rt通用寄存器;
mtc0 rt, rd 将rt通用寄存器中内容传输到CP0中寄存器rd;
mfhi/mflo rt 将CP0的hi/lo寄存器内容传输到rt通用寄存器中;
mthi/mtlo rt 将rt通用寄存器内容传输到CP0的hi/lo寄存器中;
CP0 冒险
当MIPS体系结构演进到MIPS IV的64位架构后,新增了两条指令dmfc0和dmtc0,向CP0的寄存器中读/写一个64bit的数据。
前面提到,MIPS体系结构是一个无互锁,高度流水的五级pipeline架构,这就意味着,前一条指令如果尚未执行完,后一条指令有可能已经进入了取指令/译码阶段。这样,就有可能发生所谓的CP0冒险(CP0 Hazard)现象。简单地说,就是mfc和mtc指令的执行速度是比较慢的,因此,开始执行完下一条指令时,有可能CP0寄存器的值尚未最后传输到指定的目标通用寄存器中。此时,如果读取该通用寄存器,有可能并未得到正确的值。这就是所谓的CP0冒险现象。
为了避免CP0冒险,我们在编程时需要在CP0操作指令的后面加上一条与前一条指令的目的通用寄存器无关的指令,也就是所谓的延迟槽(delay slot)。如果对性能不敏感,可以考虑CP0操作后插入足够多的nop指令填充延迟槽。
例如,经常在异常处理例程(exception handler)中出现的内容:
mfc0 k0, $cause |
另外一种软件方式就是插入一条ehb指令,比如:
mtc0 t0, SR |
其中ehb为exception hazard barrier,这个主要有MIPS的pipe lines引起,大致可以理解为由于MIPS采用的流水线(pipe lines)结构,即使在异常处理代码中(这里由于改变了状态寄存器情况类似),由于流水线的作用,异常处理结束时,其下一条(可能超过一条,依赖流水线的设计)仍然被预取执行,这样由于CPU的特权级别发生了改变,但被流水线预取的指令并不知道这些,因而导致严重的安全性问题。为了避免这种情况发生,MIPS专门使用了ehb指令。类似的指令还包括eret,即从异常(原子的,atomically)返回。
另外,SSNOP指令也值得注意,它可以自动知道需要停顿的周期数。
MIPS的异常
精确异常
精确异常的概念:在运行流程中没有任何多余效应的异常。即当异常发生时,在受害指令之前的指令被完全执行,而受害指令及后面的指令还没开始执行(注:说受害指令及后面的指令还没做任何事情是不对的,实际上受害指令是处于其指令周期的第三阶段刚完成,即ALU阶段刚完成)。精确异常有助于保证软件设计上不受硬件实现的影响。
CP0中的EPC寄存器用于指向异常发生时指令跳转前的执行位置,一般是受害指令地址。当异常时,是返回这个地址继续执行。但如果受害指令在分支延迟槽中,则会硬件自动处理使EPC往回指一条指令,即分支指令。在重新执行分支指令时,分支延迟槽中的指令会被再执行一次。
精确异常的实现对流水线的流畅性是有一定的影响的,如果异常太多,系统执行效率就会受到影响。
异常类型
异常又分常规异常和中断两类。常规异常一般为软件的异常,而中断一般为硬件异常,中断可以是芯片内部,也可以是芯片外部触发产生。
MIPS系统把重启看作一个不可回归的异常来处理。
- 冷启动:CPU硬件完全被重新配置,软件重新加载;
- 热启动:软件完全重新初始化;
其中,Exception 0-5, 8-11, 13, 23这几个异常类型较为常见。
Exception 0:Interrupt,外部中断。它是唯一一个异步发生的异常。之所以说中断是异步发生的,是因为相对于其他异常来说,从时序上看,中断的发生是不可预料的,无法确定中断的发生是在流水线的哪一个阶段。MIPS的五级流水线设计如下:
IF, RD, ALU, MEM, WB。MIPS处理器的中断控制部分有这样的设计:在中断发生时,如果该指令已经完成了MEM阶段的操作,则保证该指令执行完毕。反之,则丢弃流水线对这条指令的工作。除NMI外,所有的内部或外部硬件中断(Hardware Interrupt)均共用这一个异常向量(Exception Vector)。前面提到的CP0中的Counter/Compare这一对计数寄存器,当Counter计数值和Compare门限值相等时,即触发一个硬件中断。Exception 1:TLB Modified,内存修改异常。如果一块内存在TLB映射时,其属性设定为Read Only,那么,在试图修改这块内存内容时,处理器就会进入这个异常。显然,这个异常是在Memory阶段发生的。但是,按“精确异常”的原则,在异常发生时,ALU阶段的操作均无效,也就是说,向内存地址中的写入操作,实际上是不会被真正执行的。这一判断原则,也适用于后面的内存读写相关的异常,包括TLB Miss/Address Error/Watch等。
Exception 2/3:TLB Miss Load/Write,如果试图访问没有在MMU的TLB中映射的内存地址,会触发这个异常。在支持虚拟内存的操作系统中,这会触发内存的页面倒换,系统的Exception Handler会将所需要的内存页从虚拟内存中调入物理内存,并更新相应的TLB表项。
Exception 4/5:Address Error Load/Write,如果试图访问一个非对齐的地址,例如lw/sw指令的地址非4字节对齐,或lh/sh的地址非2字节对齐,就会触发这个异常。一般地,操作系统在Exception Handler中对这个异常的处理,是分开两次读取/写入这个地址。虽然一般的操作系统内核都处理了这个异常,最后能够完成期待的操作,但是由于会引起用户态到内核态的切换,以及异常的退出,当这样非对齐操作较多时会严重影响程序的运行效率。因此,编译器在定义局部和全局变量时,都会自动考虑到对齐的情况,而程序员在设计数据结构时,则需要对对齐做特别的斟酌。
Exception 6/7:Instruction/Data Bus Error,一般地原因是Cache尚未初始化的时候访问了Cached的内存空间所致。因此,要注意在系统上电后,Cache初始化之前,只访问Uncached的地址空间,也就是0xA0000000-0xBFFFFFFF这一段。默认地,上电初始化的入口点0xBFC00000就位于这一段。(某些MIPS实现中可以通过外部硬线连接修改入口点地址,但为了不引发无法预料的问题,不要将入口点地址修改为Uncached段以外的地址)
Exception 8:Syscall,系统调用的正规入口,也就是在用户模式下进入内核态的正规方式。我们可以类比x86下Linux的系统调用0x80来理解它。它是由一条专用指令syscall触发的。
Exception 9:Break Point,绝对断点指令。和syscall指令类似,它也是由专用指令break触发的。它指示了系统的一些异常情况,编程人员可以在某些不应当出现的异常分支里面加入这个指令,便于及早发现问题和调试。我们可以用高级语言中的assert机制来类比理解它。最常见的Break异常的子类型为0x07,它是编译器在编译除法运算时自动加入的。如果除数为0则执行一条break 0x07指令。这样,当出现被0除的情况时,系统就会抛出一个异常,并执行Coredump,以便于程序员定位除0错误的根因。
Exception 10:RI,执行了没有定义的指令,系统就会发生这个异常。
Exception 11,Co-Processor Unaviliable,试图访问的协处理器不存在。比如,在没有实现CP2的处理器上执行对CP2的操作,就会触发这个异常。
Exception 12,Overflow,算术溢出。会引起这个异常的指令,仅限于加减法中的带符号运算,如add/addi这样的指令。因此,一般地,编译器总是将加减法运算编译为addiu这样的无符号指令。由于MIPS处理异常需要一定的开销,这样可以避免浪费。
Exception 13,Trap,条件断点指令。它由trap系列指令引发。与Break指令不同的是,只有满足断点指令中的条件,才会触发这个异常。我们可以类比x86下的int 3断点异常来理解它。
Exception 14,VCEI,(不明白!谁知道是干嘛使的?)
Exceotion 15,Float Point Exception,浮点协处理器1的异常。它由CP1自行定义,与CP1的具体实现相关。其实就是专门为CP1保留的异常入口。Exception 16,协处理器2的异常,和前一个异常一样,是和CP2的具体实现相关的。
Exception 23,Watch异常。前面讲到Watch寄存器可以监控一段内存,当访问/修改这段内存时,就会触发这个异常。在异常处理例程中,通过异常栈可以反推出是什么地方对这段内存进行了读/写操作。这个异常是用来定位内存意外写坏问题的一柄利器。
异常处理过程-硬件部分
异常发生时,跳转前最后被执行的指令是其MEM阶段刚好被执行完的那条指令。受害指令是其ALU阶段刚好执行完的那条指令。
异常发生时,会跳到异常向量入口中去执行。MIPS的异常向量有点特殊,它一般只个2个或几个中断向量入口,一个入口给一般的异常使用,一个入口给 TLB miss异常使用(这样的话,可以省下计算异常类型的时间。在这种机制帮助下,系统只用13个时钟周期就可以把TLB重填好)。
CP0寄存器中有个模式位,SR(BEV),只要设置了,就会把异常入口点转移到非缓冲内存地址空间中(kseg1)。
MIPS对异常的处理的哲学是给异常分配一些类型,然后由软件给它们定义一些优先级,然后由同一个入口进入异常分配程序,在分配程序中根据类型及优先级确定该执行哪个对应的函数。这种机制对两个或几个异常同时出现的情况也是适合的。
下面是当异常发生时MIPS CPU所做的事情:
- 设置EPC指向回归的位置;
- 设置SR(EXL)强迫CPU进入kernel态,并禁止所有中断响应。
- 设置Cause寄存器,以使软件可以得到异常的类型信息;还有其它一些寄存器在某些异常时会被设置;
- CPU开始从异常入口取指令,然后以后的所有事情都交由软件处理了。
k0和k1寄存器用于保存异常处理函数的地址。
异常处理函数执行完成后,会回到异常分配函数那去,在异常分配函数里,有一个eret指令,用于回归原来被中断的程序继续执行;eret指令会原子性地把中断响应打开(置SR(EXL)),并把状态级由kernel转到user级,并返回原地址继续执行。
异常入口点位于kseg0的底部,是硬件规定的。
异常处理过程-软件部分
MIPS的异常处理,通常来说,和其他体系结构的异常/中断/陷阱处理,没有太多的区别,总的来说分为三段:
- 保存现场寄存器组(Register File)。在堆栈中开辟一段区域,将32个通用寄存器和CP0的相关寄存器,如Status,BadVaddr,Cause等,保存在这段内存中。其中尤为重要的是EPC,EPC指向引发异常时的指令。
在这个步骤中,首先保存的应该是通用寄存器组,随后是epc/cause/status/badvaddr这几个epc0中的寄存器。从cp0到内存的数据传输必须通过通用寄存器。一般地,编程时的约定是使用k0和k1这两个寄存器暂存。如下例:(适用于32位MIPS模式)
sw zero, 0(sp) |
异常处理部分。以Address Error异常为例,当异常发生时,根据保存的BadVaddr,调用两次非对齐加载/存储指令,对内存地址进行数据的读写操作。
返回。将保存在堆栈中的寄存器组内容恢复。
从异常状态返回的这个动作,是由硬件完成的。它必须同时完成三个操作:
- 将SR寄存器恢复;
- 返回到EPC寄存器所指向的地址继续执行;
- 恢复到用户态。如《See MIPS Run》提到的,如果这三个过程没有能够“原子地”执行完毕,那么将会导致一个安全漏洞,用户有可能在某种情况下僭越CPU内核态设定的壁垒,从而非法获得管理员权限。
在MIPS I和MIPS II处理器中,使用rfe这条指令,来进行“从异常中恢复”,也就是恢复SR寄存器,并且将系统从内核态恢复到用户态。但这条指令并没有将执行的指令地址返回到异常发生的指令处。这项工作应当由在此之前的一条JR指令来执行。这样,从异常中返回的相关汇编代码应当为:
mfc k0, epc |
在MIPS III及以后的处理器中,从异常中返回不再需要这样的繁文缛节,只需要一条eret指令便万事俱备了。
MIPS的中断
MIPS CPU有8个独立的中断位(在Cause寄存器中),其中,6个为外部中断,2个为内部中断(可由软件访问)。一般来说,片上的时钟计数/定时器,会连接到一个硬件位上去。
SR(IE)位控制全局中断响应,为0的话,就禁止所有中断;
SR(EXL)和SR(ERL)位(任何一个)如果置1的话,会禁止中断;
SR(IM)有8位,对应8个中断源,要产生中断,还得把这8位中相应的位置1才行;
中断处理程序也是用通用异常入口。但有些新的CPU有变化。
在软件中实现中断优先级的方案:
- 给各种中断定优先级;
- CPU在运行时总是处于某个优先级(即定义一个全局变量);
- 中断发生时,只有等于高于CPU优先级的中断优先级才能执行;(如果CPU优先级处于最低,那么所有的中断都可以执行);
- 同时有多个中断发生时,优先执行优先级最高的那个中断程序;
MIPS的原子操作
MIPS为支持操作系统的原子操作,特地加了一组指令 ll/sc。它们这样来使用:
先写一句atomic_block:
LL XX1, XXX2
….
sc XX1, XXX2
beq XX1, zero, automic_block
….
在ll/sc中间写上你要执行的代码体,这样就能保证写入的代码体是原子执行的(不会被抢占的)。
其实,LL/sc两语句自身并不保证原子执行,但它耍了个花招:
用一个临时寄存器XX1,执行LL后,把XXX2中的值载入XX1中,然后会在CPU内部置一个标志位,我们不可见,并保存XXX2的地址,CPU会监视它。在中间的代码体执行的过程中,如果发现XXX2的内容变了(即是别的线程执行了,或是某个中断发生了),就自动把CPU内部那个标志位清0。执行sc 时,把XX1的内容(可能已经是新值了)存入XXX2中,并返回一个值存入XX1中,如果标志位还为1,那么这个返回的值就为1;如果标志位为0,那么这个返回值就为0。为1的话,就表明这对指令中间的代码是一次性执行完成的,而不是中间受到了某些中断,那么原子操作就成功了;为0的话,就表明原子操作没成功,执行后面beq指令时,就会跳转到ll指令重新执行,直到原子操作成功为止。
所以,我们要注意,插在LL/sc指令中间的代码必须短小。
据经验,一般原子操作的循环不会超过3次。
MIPS的大小端
硬件上也有大端小端问题,比如串口通讯,一个字节一个字节的发,首先是低位先发出去。
还有显卡的显示,比如显示黑白图像,在屏幕上一个点对应显存中的一位,这时,这个位对应关系就是屏幕右上角那个点对应显存第一个字节的7号位,即最高位。第一排第8位点对应第一个字节的0号位。
MIPS的MMU
ASID
ASID是与虚拟页高位配合使用。用于描述在TLB和Cache中的不同的线程,只有8位,所以最多只能同时运行256个线程。这个数字一般来说是够的。如果超过这个数目了,就要把Cache刷新了重新装入。所以,在这点上,与x86是不同的。
TLB的refill过程-硬件部分
CPU先产生一个虚拟地址,要到这个地址所对应的物理地址上取数据(或指令)或写数据(或指令)。
低13位被分开来,然后高19位成为VPN2,和当前线程的ASID(从EntryHi(ASID)取)一起配合与TLB表中的项进行比较(在比较过程中,会受到PageMask和G标志位的影响)。
如果有匹配的项,就选择那个。虚拟地址中的第12位用于选取是用左边的物理地址项还是用右边的物理地址项。
然后就会考察V和D标志位,V标志位表示本页是否有效,D表示本页是否已经脏了(被写过)。
如果V=0,或D=1,就会引发翻译异常,BadVAddr会保存现在处理的这个虚拟地址,EntryHi会填入这个虚拟地址的高位,还有Context中的内容会被重填。然后就会考察C标志位,如果C=1,就会用缓冲作中转,如果C=0,就不使用缓冲。
这几级考察都通过了之后,就正确地找到了那个对应的物理地址。
如果没有匹配的项,就会触发一个TLB refill异常,然后后面就是软件的工作了。
TLB的refill过程-软件部分
- 计算这个虚拟地址是不是一个正确的虚拟地址,在内存页表中有没有与它对应的物理地址;如果没有,则调用地址错误处理函数;
- 如果在内存页表中找到了对应的物理地址,就将其载入寄存器;
- 如果TLB已经满了,就用random选取一个项丢弃;
- 复制新的项进TLB。
MIPS的高速缓冲
MIPS一般有两到三级缓冲,其中第一级缓冲数据和指令分开存储。这样的好处是指令和数据可以同时存取,提高效率。但缺点是提高了复杂度。第二级缓冲和第三级缓冲(如果有的话)就不再分开存放啦。
缓冲的单元叫做缓冲行(cache line)。每一行中,有一个tag,然后后面接的是一些标志位和一些数据。缓冲行按顺序线性排列起来,就组成了整个缓冲。
cache line的索引和存取有一套完整的机制。
